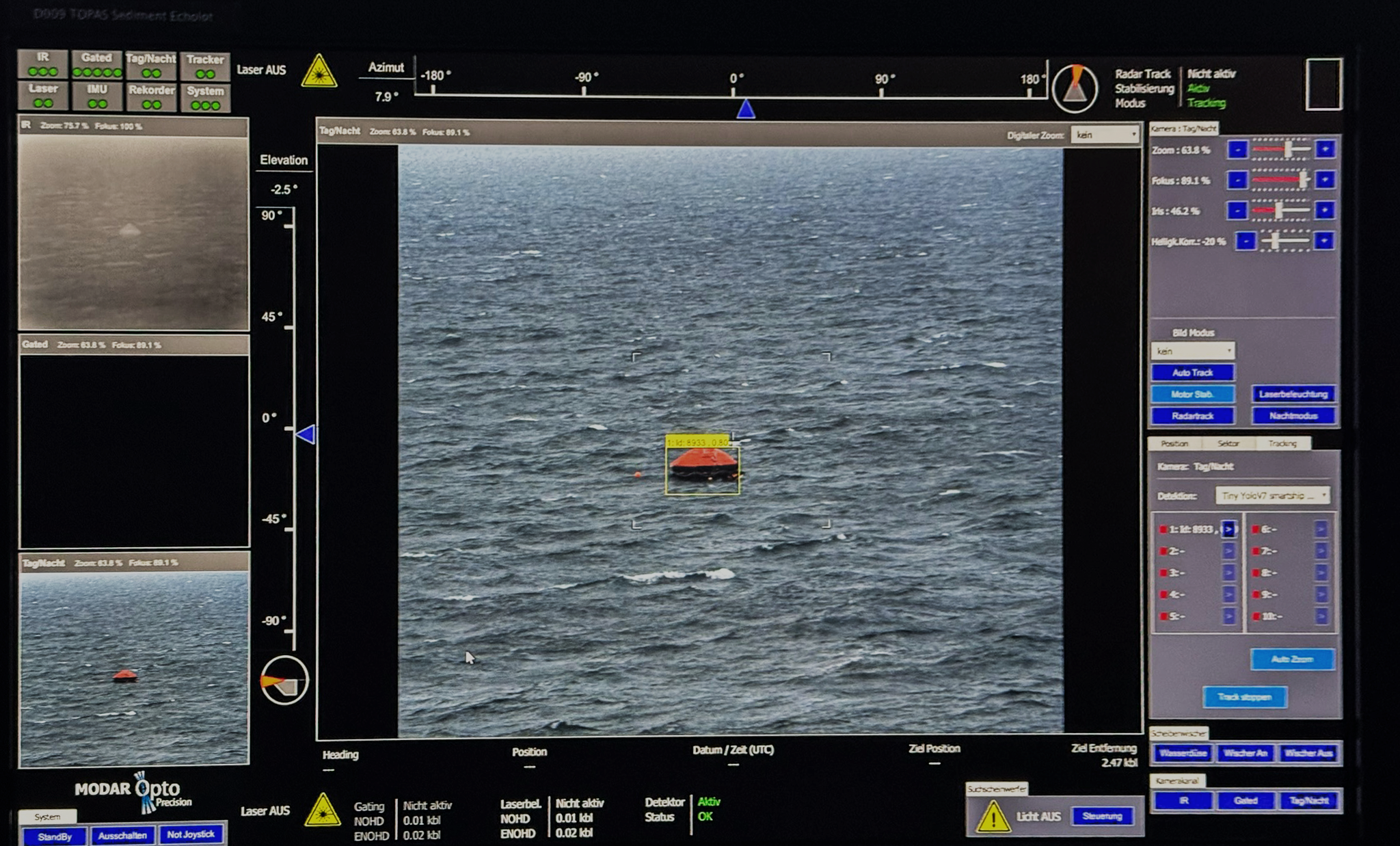
Data Logging and Analytics


Source Validation
We validate data directly at the source to ensure correctness, completeness, and temporal consistency. Incoming signals are checked for schema conformity, plausibility, and anomalies before they enter the pipeline. This prevents corrupted or biased data from propagating downstream.


Storage Strategy
Validated data is stored in a structured, versioned, and traceable manner optimized for time-series access. Our storage design preserves raw data while maintaining derived, query-ready representations. This guarantees reproducibility and long-term usability for analytics and model training.
Processing Toolkit
We provide a flexible processing toolkit for normalization, labeling, aggregation, and feature extraction. All transformations are deterministic and fully auditable. This ensures the resulting datasets are consistent, explainable, and ideal for machine learning workflows.